大模型API编程-260320
更新-260320 | 发布-260319
本实验演示使用 Jetson 实验箱部署 OpenAI 兼容接口的大模型接口服务,使用该模型服务接口构建基于控制台的对话应用。
原理和代码解读,可参考 CG 平台相关说明。本文档主要描述操作相关。
登录 CG平台↗,对应 “61724. 实验4-3:大模型RestAPI编程开发”:
- 点击左上角 我的课程,选择 NLP实验箱
- 点击顶部水平导航栏的 作业,找到下方 61724. 实验4-3:大模型RestAPI编程开发,点击可进入
目录
实验箱简介
和常见的台式机很相似。视觉实验箱的相关部件有:
- 主机。有个小小机箱,内部是英伟达开发板(Nvidia Jetson)。
- 屏幕。支持 HDMI 接口的屏幕,都可以通过 HDMI 线连接到 Jetson 开发板。
- 鼠标和键盘。常见的鼠标和键盘,通过 USB 连接 Jetson 开发板。
- 操作系统。Ubuntu,Linux 的发行版的一种。(常见操作系统有: Windows、MacOS、Linux,等)
- 机械臂。由 Jetson 开发板控制的一个外部设备。
上电开机
- 视觉实验箱配有 1 个电源,一端连实验箱,另一端插头插在桌子下面的插座上。
- 桌子下面有个带开关的的立方体插座。按下开关,电源指示灯亮,即表明接通电源。
- 稍等片刻可完成启动。视觉实验箱的机械臂站立起来,且屏幕显示 Ubuntu 的主界面,就启动完成。
熟悉 Linux 命令
请参考 视觉实验-260304 | 熟悉 Linux 命令↗
安装 Ollama
Ollama 简介
Ollama是一款面向大语言模型(LLM)的本地化部署与运行时管理框架,支持在个人计算设备或服务器端高效运行开源预训练模型。
其采用容器化架构实现模型的标准化封装与分发,通过动态量化技术优化内存占用,并提供与OpenAI API兼容的RESTful接口,便于集成至现有AI应用生态。
Ollama支持Llama、Qwen、DeepSeek等主流架构的模型仓库管理,具备异构计算资源调度能力,可基于CPU或GPU实现低延迟推理。
该工具广泛应用于数据隐私敏感场景的私有化部署、边缘计算环境下的离线推理及学术研究的模型微调与评测,为大规模语言模型的本地化应用提供了轻量级技术基座。
安装 Ollama 到 Jetson 开发板
使用开发板已有的 jetson 用户(初始密码:yahboom)执行以下操作。
方法1(首选)
mkdir -p ~/tmp26/03 # 创建临时目录,目录名字可随意取
cd ~/tmp26/03 # 切换到临时目录
# 将已下载的 ollama 压缩包 从某个开发板复制到临时目录中
scp jetson@172.18.145.179:/home/jetson/tmp26/03/ollama.tar.gz .
# 解开压缩包
tar zxvf ollama.tar.gz
cd ollama_jetsonv5 # 切换到当前目录下的子目录(解压缩生成的)
sudo mv ollama /usr/local/bin/ # 移动文件到目标目录
sudo mv lib /usr/local/lib/ollama # 移动目录到目标目录
# 修改文件 ollama 的权限,让所有用户都可执行 ollama
chmod a+x /usr/local/bin/ollama
scp 命令最后有个点,表示复制到当前目录中。不要遗漏。
scp 命令中 172.18.145.179 是实验室的某个 Jetson 开发板,在相关目录中已经下载了 ollama 压缩包。
Linux 文件权限 和 chmod 命令相关,可自行网上查找或与AI交流获得更多信息。
方法2(其次)
mkdir -p ~/tmp26/03 # 创建临时目录,目录名字可随意去
cd ~/tmp26/03 # 切换到临时目录
# 从网上下载 ollama 压缩包到临时目录中
wget https://pan.educg.net/f/voqt9/ollama.tar.gz
# 解开压缩包
tar zxvf ollama.tar.gz
cd ollama_jetsonv5 # 切换到当前目录下的子目录(解压缩生成的)
sudo mv ollama /usr/local/bin/ # 移动文件到目标目录
sudo mv lib /usr/local/lib/ollama # 移动目录到目标目录
# 修改文件 ollama 的权限,所有用户都可执行 ollama
chmod a+x /usr/local/bin/ollama
方法2 和 方法1 基本一致,除了 ollama 压缩包是用 wget 命令从网上下载的。
方法3(备选)
curl -fsSL https://ollama.com/install.sh | sh
Ollama 官网安装指令。网络原因,不一定能在实验室安装成功。
启动qwen
-
新启 终端 Terminal #1,在终端中执行以下命令:
ollama serve # 启动 API 服务(默认 11434 端口) -
再启 终端 Terminal #2,在终端中执行以下命令:
ollama run qwen2.5:3b # 加载qwen2.5:3b量化模型,没有则下载Jetson 开发板上若没有 qwen2.5:3b,会从网上下载。下载大约需要几分钟。
ollama 常用管理
ollama list # 查看已下载模型
ollama pull <模型名> # 仅下载不运行
ollama rm <模型名> # 删除本地模型
ollama ps # 查看正在运行的模型进程
测试 Restful 接口
再启 终端 Terminal #3,在终端中执行以下命令:
curl --location --request POST "http://127.0.0.1:11434/v1/chat/completions" --header "Content-Type: application/json" --header "Authorization: Bearer EMPTY" --data-raw '{"model": "qwen2.5:3b", "messages":[{"role": "user", "content": "hi"}]}'
OpenAI兼容Restful接口
OpenAI兼容接口常用接口如下:
POST https://api.openai.com/v1/chat/completions
参数列表:
- model:必选;模型名称;要使用的模型的 ID;字符串
- message:必选;消息内容;要发送给大模型的消息数组,每条数据必须包含role和content字段;数组
- stream:可选;流式输出;是否启动流式输出;布尔;默认为false
- temperature:可选;采样温度;0 和 2 之间的采样温度。较高的值(例如 0.8)使输出更加随机,而较低的值(例如 0.2)使其更加焦虑和确定性;浮点数;默认值为1
- max_tokens:可选;可以在聊天完成中生成的最大数量的令牌;整数;默认值为null
返回:
- 返回一个聊天完成对象,或者如果请求是流式的,则返回一个流序列的聊天完成 chunk 对象。
搭建 Python 虚拟环境
-
在 终端 #3 中执行以下命令创建 Python 虚拟环境:
conda create -n py0320 python=3.12py0320 是给虚拟环境起的名字。可以是其他名字,比如 llm312。
CG 平台该实验的 2.4 API编程 给出了另一种方案,暂不采用。
-
激活刚创建的虚拟环境:
conda activate py0320py0320 是刚创建的虚拟环境的名字。激活后,命令行提示符首部会出现
(py0320)字样,表示该虚拟环境已激活。
相关参考:
- 如果 conda 不存在,请参考:视觉实验-260304 | 第1步:安装conda↗。
- 虚拟环境管理,请参考:视觉实验-260304 | conda常用命令↗。
运行样例程序
-
在 终端 #3,建议新建目录存放样例程序:
mkdir -p ~/ailab/260320 cd ~/ailab/260320 -
新建 main.py
可在 Jetson 开发板上新建 main.py:
- 在终端执行:
vim main.py - 复制 main.py 样例程序的代码
- 在终端 vim 窗口中按
i键 - 鼠标
右键,选paste - 在终端 vim 窗口中,先按
esc键,再输入:wq,并按回车键
新建文件 main.py 完成后,还可以执行
cat main.py看看文件内容。还可以用 MobaXterm 软件或 powershell 等 ssh 方式登录 Jetson 开发板,然后新建 main.py。或在本地电脑新建 main.py,再通过 scp 命令复制到 Jetson 开发板指定目录中。此处从略。
- 在终端执行:
-
在虚拟环境 py0320 中运行样例程序:
(py0320) jetson@jetson-Yahboom:~/ailab/260320$ python3 main.py执行
python3 main.py即可。列出行首是(py0320)的命令行提示符是提醒要在虚拟环境中执行。新建的虚拟环境还需要安装一些 Python 包,比如 requests。否则报错:requests 没有找到。
(py0320) jetson@jetson-Yahboom:~/ailab/260320$ pip3 install requests执行
pip3 install ...即可。列出行首是(py0320)的命令行提示符是提醒要在虚拟环境中执行。安装缺少的包以后,再次执行样例程序,并和 qwen 交互。
结果样例截图:
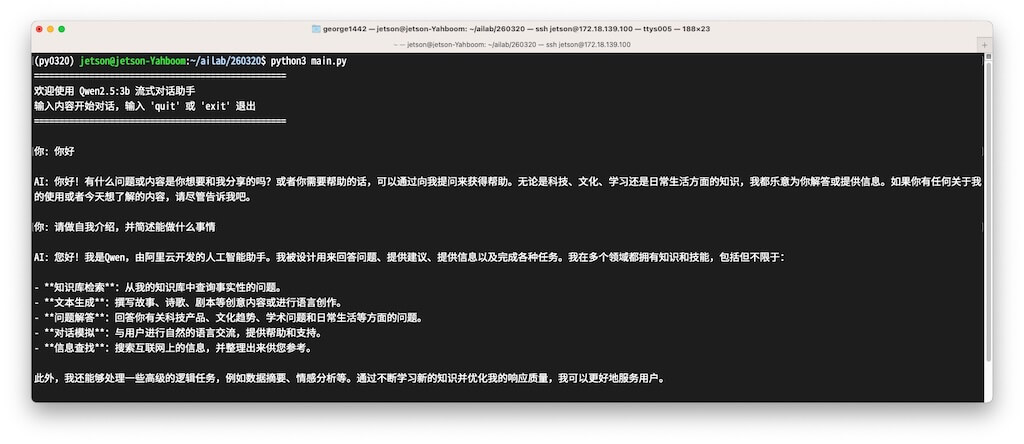
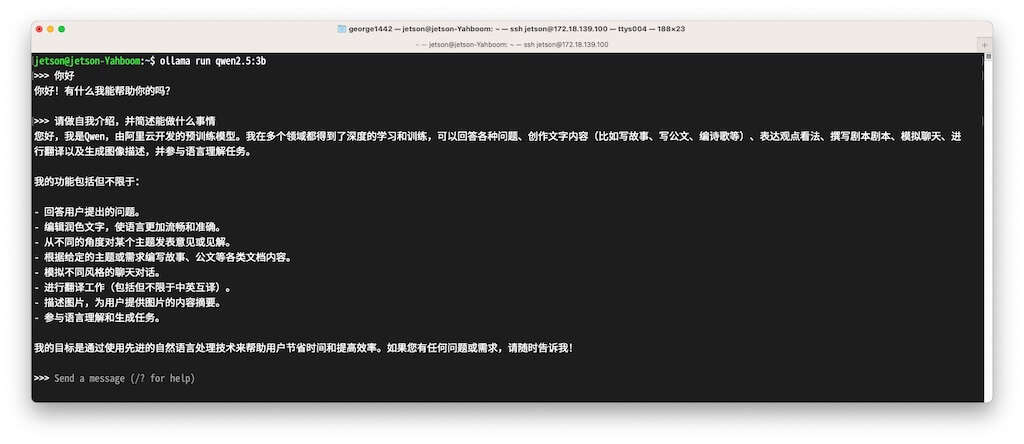
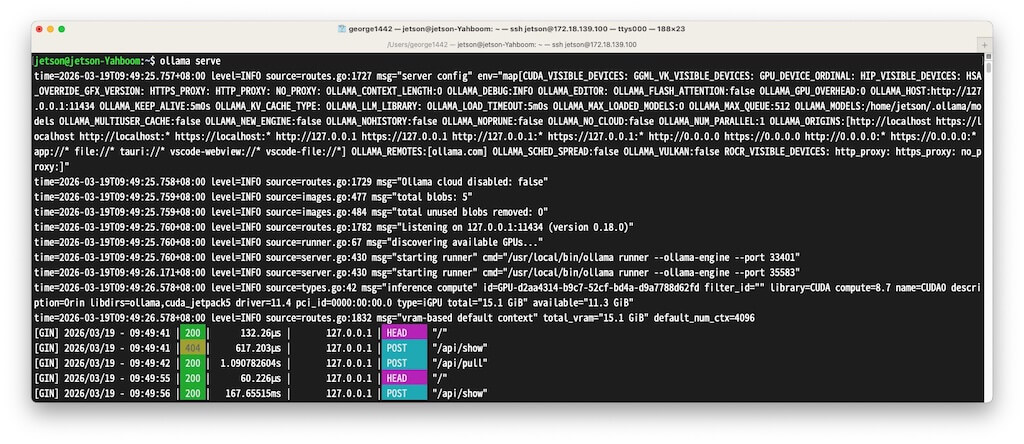
main.py样例程序
样例程序如下:
import requests
import json
API_URL = "http://127.0.0.1:11434/v1/chat/completions"
MODEL = "qwen2.5:3b"
API_KEY = "EMPTY"
def chat(messages):
"""发送流式请求到API"""
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
payload = {
"model": MODEL,
"messages": messages,
"stream": True
}
response = requests.post(API_URL, headers=headers, json=payload, stream=True)
response.raise_for_status()
return response
def main():
messages = []
print("=" * 50)
print("欢迎使用 Qwen2.5:3b 流式对话助手")
print("输入内容开始对话,输入 'quit' 或 'exit' 退出")
print("=" * 50)
while True:
user_input = input("\n你: ").strip()
if not user_input:
continue
if user_input.lower() in ["quit", "exit", "q"]:
print("再见!")
break
messages.append({"role": "user", "content": user_input})
print("\nAI: ", end="", flush=True)
try:
response = chat(messages)
full_content = ""
for line in response.iter_lines():
if line:
line = line.decode("utf-8")
if line.startswith("data: "):
data = line[6:]
if data == "[DONE]":
break
try:
json_data = json.loads(data)
if "choices" in json_data and len(json_data["choices"]) > 0:
delta = json_data["choices"][0].get("delta", {})
if "content" in delta:
content = delta["content"]
print(content, end="", flush=True)
full_content += content
except json.JSONDecodeError:
continue
print()
if full_content:
messages.append({"role": "assistant", "content": full_content})
except requests.exceptions.RequestException as e:
print(f"\n请求错误: {e}")
messages.pop()
if __name__ == "__main__":
main()
实验任务
-
修改示例代码中的stream参数为false,补充非流式输出处理程序,运行程序验证非流式输出的效果。
-
Ollama库同时提供了自定义Python库和接口,请查阅资料,使用Ollama接口实现基于控制台的大模型对话程序。
-
流式输出(streaming)与非流式输出相比,在用户体验和数据传输上有什么优势?
关机&复原&离开
‼️实验结束离开前,请各位同学完成相关事项。详见:视觉实验-260304 | 关机&复原&离开↗