RAG实验-260417
更新-260417 | 发布-260410
本文档参考 CG 平台 | NLP 实验箱 | 实验5-3:ChatPDF大模型应用开发 编写而成。本文主要描述操作步骤,源码解释请参考 CG 平台。
实验简介
实验内容
本实验将使用 RAG(Retrieval-Augmented Generation,检索增强生成)系统构建一个专门针对 PDF 文档的智能问答系统。与通用 RAG 系统不同,本实验专注于 PDF 文档的处理,并提供了基于 Gradio 的 Web 界面,让用户可以通过友好的图形界面与 PDF 文档进行交互。本实验将学习如何构建一个完整的 PDF 专用 RAG 系统,包括 PDF 文档加载、向量化存储、相似度检索、答案生成以及 Web 界面开发等核心模块。
实验要点
通过本次实验,希望能掌握以下要点:
- 了解 RAG 系统的基本原理和工作流程
- 学习 LangChain 框架的使用方法
- 掌握 PDF 文档加载、文本分割、向量化存储等关键技术
- 学会使用 FAISS 进行高效的向量检索
- 理解如何将检索到的上下文信息与大语言模型结合生成答案
- 学习使用 Gradio 构建 Web 界面,提供友好的用户交互体验
- 理解 PDF 专用 RAG 系统与通用 RAG 系统的区别和优势
实验环境
主要涉及以下软件:
- Python 3
- LangChain 框架
- FAISS 向量数据库
- Qwen 大语言模型(通过 API 端点访问)
- Gradio Web 框架
RAG介绍
RAG(Retrieval-Augmented Generation,检索增强生成)系统是一种结合了信息检索和生成式 AI 的先进技术。其核心思想是:当用户提出问题时,系统首先从知识库中检索相关的文档片段,然后将这些上下文信息与大语言模型结合,生成更准确、更有依据的答案。相比直接使用大语言模型,RAG 系统能够:
- 提供事实依据:答案基于实际文档内容,而非模型训练数据
- 减少幻觉:通过检索到的上下文约束,降低模型编造信息的可能性
- 支持知识更新:只需更新知识库,无需重新训练模型
- 提高准确性:针对特定领域的知识库能够提供更专业的回答

主要流程:
- 数据入库:读取 PDF 文档并切成小块,并把这些小块经过编码embedding后,存储在一个向量数据库中;
- 相关性检索:用户提出问题,问题经过编码,再在向量数据库中做相似性检索,获取与问题相关的信息块context,并通过重排序算法,输出最相关的N个context;
- 问题输出:相关段落context + 问题组合形成prompt输入大模型中,大模型输出一个答案或采取一个行动
本实验使用的 RAG 系统基于 LangChain 框架构建,采用模块化设计,代码结构清晰,便于理解和扩展。与通用 RAG 系统相比,本系统专门针对 PDF 文档进行了优化,并提供了 Web 界面支持。
项目结构介绍
本项目的代码采用模块化设计,主要包含以下目录和文件:
chatpdf/
├── config/ # 配置模块
│ ├── __init__.py
│ └── settings.py # 配置文件
├── models/ # 模型封装
│ ├── __init__.py
│ ├── llm.py # LLM 模型封装
│ └── embedding.py # 嵌入模型封装
├── chains/ # RAG 链
│ ├── __init__.py
│ └── rag_chain.py # RAG 链实现
├── utils/ # 工具函数
│ ├── __init__.py
│ └── pdf_loader.py # PDF 文档加载工具(仅支持 PDF)
├── vectorstore/ # 向量存储目录(自动生成)
├── main.py # 主程序入口(命令行接口)
├── gradio_app.py # Gradio Web 应用
├── requirements.txt # 依赖文件
└── handbook.md # 本实验手册
相关信息
相关信息如下:
- 账号 / 密码:jetson / yahboom
- 中文输入法相关:教具相关软件安装使用↗
搭建环境
本章节用于搭建本次实验的环境,主要完成以下操作:
- 创建用于本次实验的 Python 虚拟环境,在虚拟环境中完成本次实验。不被其他项目影响,也不影响其他项目。
- 安装本次实验需要的 Python 包。
-
执行以下命令创建 Python 3.10 虚拟环境:
conda create -n rag0417 python=3.10✳️
rag0417是虚拟环境的名字,可以是其他取值。本文以 rag0417 为例。 -
激活刚创建的虚拟环境:
conda activate rag0417✳️ 激活虚拟环境后,命令行提示符首部有
(rag0417)字样,比如:(rag0417) jetson@jetson-Yahboom:~$ -
在虚拟环境中安装所需的 Python 包:
pip3 install faiss-cpu gradio==5.34.2 langchain langchain-community langchain-openai pydantic-settings pypdf✴️ 一定要把 Python 包安装到虚拟环境中。
conda常用命令
以下是常用的 conda 命令:
conda create -n rag0417 python=3.10:创建 Python 3.10 的名称是 rag0417 的虚拟环境conda remove -n rag0417 --all:删除名称是 rag0417 的虚拟环境conda activate rag0417:激活名称是 rag0417 的虚拟环境conda deactivate:在 rag0417 虚拟环境中执行该命令,可去激活(退出)rag0417 的虚拟环境conda env list:查看当前已创建了哪些虚拟环境
下载解压样例代码
参考以下步骤,下载并解压样例代码。
-
点击下载:样例代码↗
-
移动下载文件到 HOME 目录。在 Jetson 开发板上用浏览器下载时,通常下载文件存放在 ~/Downloads 目录中。执行以下命令移动文件:
mv ~/Downloads/chatpdf0417.zip ~/. -
以此执行以下命令,解压缩 zip 文件:
unzip ~/chatpdf0417.zip解压缩完成后,在 HOME 目录生成 chatpdf 子目录,完整路径是
/home/jetson/chatpdf,其中存放样例代码。
体验样例-命令行
执行以下步骤,用命令行方式体验样例。
-
构建向量存储。使用提供的知识库文件
2026jnu.pdf(2026年本科直博研究生招生专业目录) 构建向量存储:先切换到实验目录:
cd ~/chatpdf构建向量存储:
python3 main.py --mode build --file 2026jnu.pdf显示如下类似提示信息:
(rag0417) jetson@jetson-Yahboom:~/chatpdf$ python3 main.py --mode build --file 2026jnu.pdf 正在加载 PDF 文档: 2026年本科直博研究生招生专业目录.pdf 已加载 3 个文档页面 正在构建向量存储... 警告: 向量存储已存在,将被覆盖。如需增量添加,请使用 append=True 参数。 向量存储已构建并保存到: ./vectorstore -
命令行交互式查询
构建向量存储后,在实验目录中,执行以下命令启动交互式查询:
python3 main.py --mode interactive -
命令行单次查询
也可以在实验目录中,执行以下命令使用单次查询模式:
python3 main.py --mode query --question "2026江南大学本科直博研究生招生专业目录中,食品学院的招生专业有哪些?"得到如下类似信息:
(rag0417) jetson@jetson-Yahboom:~/chatpdf$ python3 main.py --mode query --question "2026江南大学本科直博研究生招生专业目录中,食品学院的招生专业有哪些?" 正在加载向量存储... 问题: 2026江南大学本科直博研究生招生专业目录中,食品学院的招生专业有哪些? 正在生成答案... 答案: 根据提供的文档内容,2026年江南大学食品学院的本科直博研究生招生专业包括: 1. 083200 食品科学与工程 2. 086003 食品工程(专业学位)
体验样例-Web
执行以下步骤,通过 Gradio Web (用 Gradio 构建的 Web 界面)体验样例。
-
在 终端Terminal 依次执行以下命令启动 Web 服务端:
先切换到实验目录:
cd ~/chatpdf启动 Web 服务端:
python3 gradio_app.py -
在 Jetson 开发板的浏览器以下3个地址之一,通过 Web 体验样例。
127.0.0.1:7860localhost:7860{Jetson开发板校园网IP地址}:7860(比如 172.18.145.63:7860)
可看到如下界面:
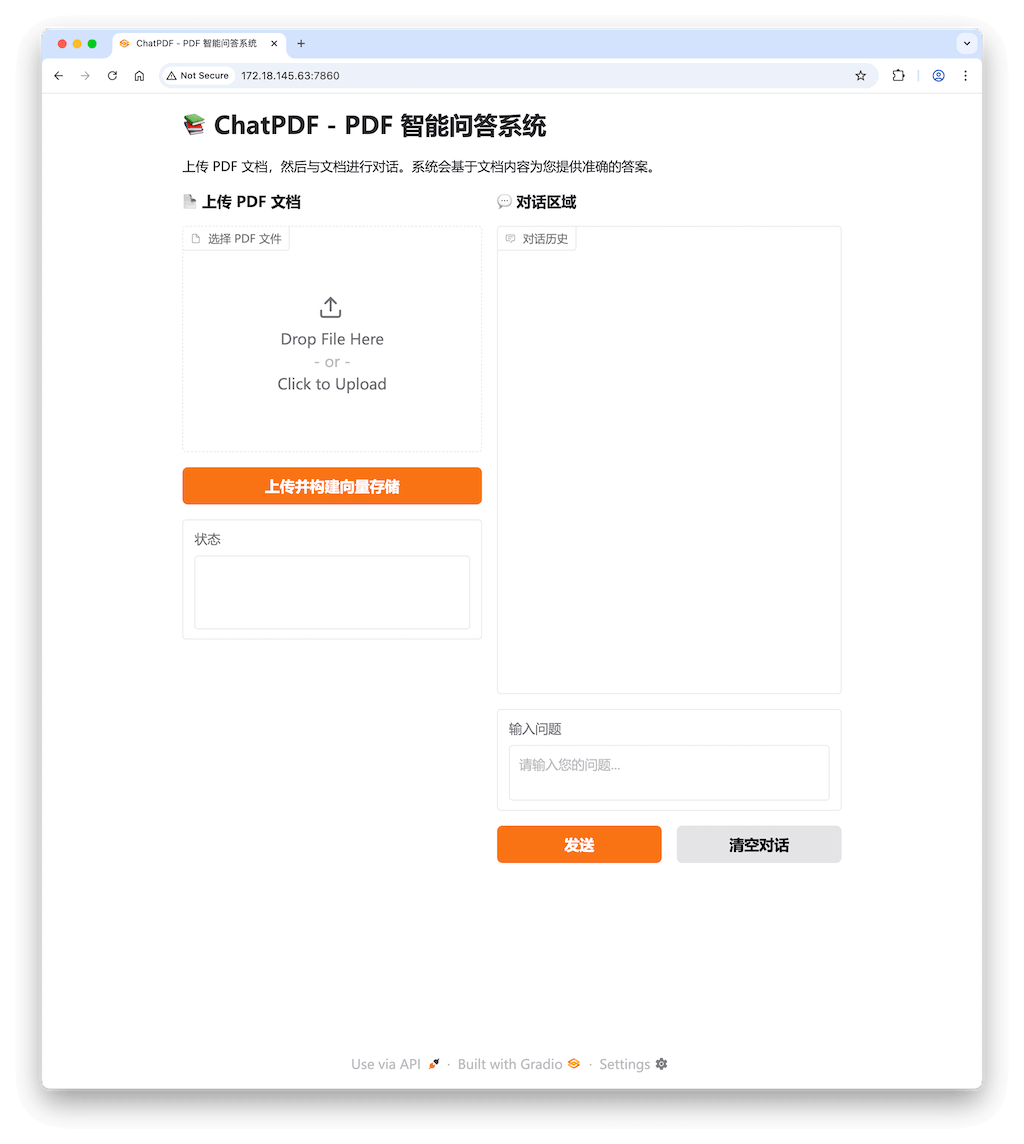
✳️ 也可以在接入校园网的电脑上,访问
{Jetson开发板校园网IP地址}:7860(比如 172.18.145.63:7860)。🚫 不是访问
0.0.0.0:7860。 -
在 Web 界面上传 pdf 文件并解析,在 Web 界面提问并得到答案。
扩展任务
尝试完成以下扩展任务:
-
多样化PDF解析:
- 尝试使用Qwen2.5-VL-7B多模态模型理解pdf内容,并提取内容进行Embedding
-
多 PDF 文档知识库:
- 修改Gradio应用,使其支持rag对话和普通对话功能
- 当存在向量数据库时,增量添加pdf文档内容
-
Gradio 界面优化:
- 研究 Gradio 的更多功能(如主题定制、组件样式等)
- 尝试添加新功能(如显示检索到的文档片段、支持多轮对话等)
- 优化界面布局和用户体验
实验报告要求
撰写实验报告,需要在实验报告中完成以下任务:
-
实验过程记录:
- 记录完整的实验步骤,包括环境搭建、向量存储构建、命令行查询测试、Web 界面使用等
- 提供关键步骤的截图或输出结果
- 记录使用自定义 PDF 文档的实验过程和结果
- 记录参数调优实验的过程和结果
-
代码理解分析:
- 分析每个模块的功能和实现原理
- 说明 RAG 系统的工作流程
- 解释向量检索和答案生成的过程
- 分析 Gradio Web 应用的实现原理
-
思考题:
- 思考题1:PDF 专用 RAG 系统相比通用 RAG 系统有什么优势和局限性?在什么场景下应该选择 PDF 专用系统?
- 思考题2:Web 界面相比命令行界面有什么优势?在什么场景下应该使用 Web 界面,什么场景下应该使用命令行界面?
- 思考题3:文档分割策略(chunk_size 和 chunk_overlap)对 PDF 文档的检索效果有什么影响?如何针对不同类型的 PDF 文档(如学术论文、技术手册、表格文档)选择合适的参数?
- 思考题4:RAG 技术在 PDF 文档处理领域有哪些潜在应用?请结合你的专业背景,谈谈 RAG 技术如何解决 PDF 文档相关的实际问题
-
问题与改进:
- 记录实验过程中遇到的问题和解决方法
- 提出对系统的改进建议
- 思考如何优化检索效果和答案质量
- 思考如何改进 Web 界面的用户体验
THE END