刷脸开门-260526
更新-260526 | 发布-260524
✳️ 目录
实验简介
关于MTCNN和FaceNet
MTCNN(Multi-task Cascaded Convolutional Networks)是一种用于人脸检测的级联卷积网络。它通过三个子网络(P-Net、R-Net、O-Net)逐步筛选候选框,同时输出人脸边界框和五个关键点(双眼、鼻子、左右嘴角)。其优势在于兼顾检测精度和速度,且对遮挡、光照有一定鲁棒性。
FaceNet 是 Google 提出的人脸识别网络,核心思想是将人脸图像直接映射到 128 维或 512 维的欧几里得嵌入空间。它使用三元组损失(triplet loss)训练,使同一个人的人脸嵌入距离小、不同人的人脸嵌入距离大。FaceNet 可直接用于人脸验证(比较距离是否小于阈值)、识别(最近邻分类)和聚类,省去了传统的 softmax 分类层,特征泛化能力很强。
简单来说:MTCNN 负责“找出人脸在哪”,FaceNet 负责“判断是谁的人脸”,两者常串联构成完整的人脸识别流程。
关于开发板
本次实验将使用 ![]() 昇腾开发板 和
昇腾开发板 和 ![]() 鲲鹏开发板,完成推理验证。
鲲鹏开发板,完成推理验证。
致谢
本文主要参考资料:gitee_夜雨飘零/Pytorch-MobileFaceNet↗。在此致谢文章作者。
实验任务
基于开发板,采用摄像头自动抓取人脸图像,小组成员的人脸能够识别,识别成功显示 “开门成功”,小组以外成员不能识别,显示 “开门失败”。
实验目的
通过本次实验,期望达成以下目的:
- 了解 MTCNN 和 FaceNet
- 做一个 刷脸开门 系统
- 进一步掌握开发板的使用
- 进一步熟悉 Linux 相关操作
- 增加解决问题的经验
对号入座
请同学们对号入座、对号使用器材。
- 16组:请移步2号桌
- 22组:请使用鲲鹏14
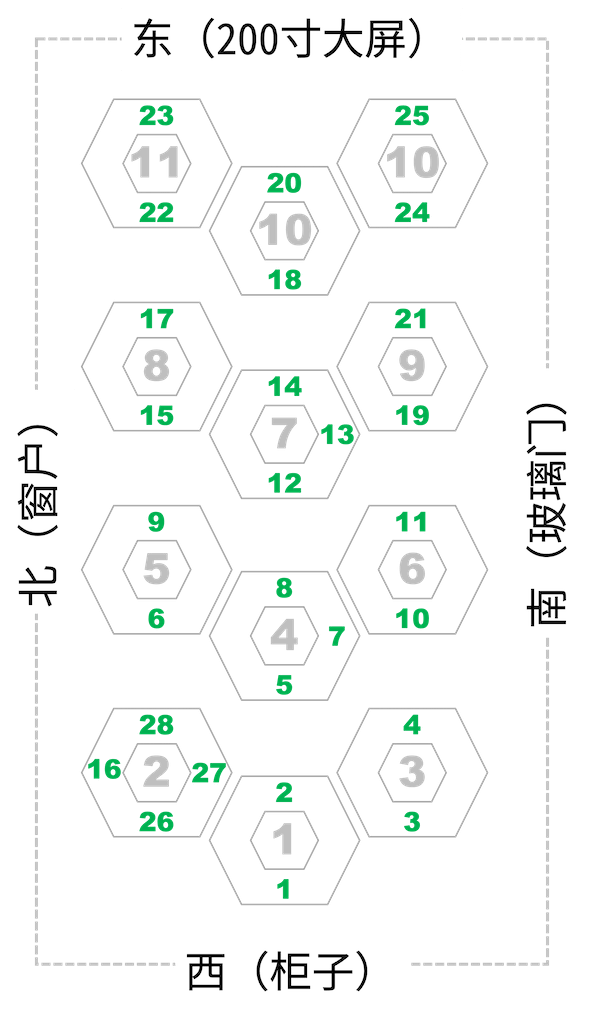
✳️ 座位安排,请对号入座
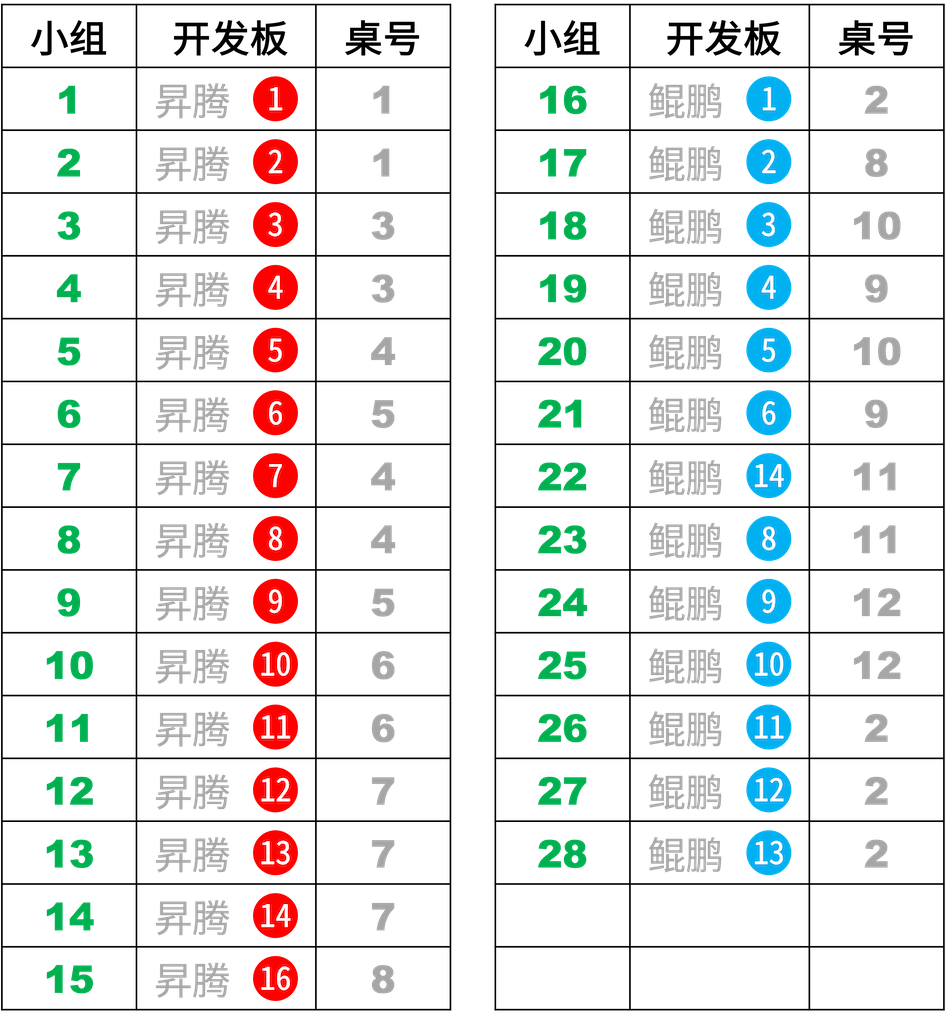
✳️ 器材安排,请对号使用
注意事项
敬请关注以下事项:
-
🚫 禁止:水杯、水瓶等,不要放在桌上。临时放桌上,则要拧紧盖子。液体泼洒会损坏开发板。
-
✅ 建议:书包等物品放实验室四周空闲处。以提高效率,并防止器材跌落(已发生跌落)。
-
✅ 建议:电源线等,都从中间穿到桌面上。以提高效率,并防止器材跌落(已发生跌落)。
0-上电开机
插上电源即可开机:
-
 昇腾:开发板上电后,3个指示灯会依次绿色常亮,表示启动正常。
昇腾:开发板上电后,3个指示灯会依次绿色常亮,表示启动正常。  鲲鹏:前面板有2个 Type-C,电源插入➡️边上那个。
鲲鹏:前面板有2个 Type-C,电源插入➡️边上那个。- 鲲鹏:拿掉顶部的磁吸盖子,看到2个绿灯亮,就表示开机完成。
1-连接外网
开发板上电开机后,先让开发板连接外网,即能访问互联网。后续创建本次实验所需的 Python 虚拟环境,需要开发板能访问外网。开发板如何连接外网,请参考:
2-获取源码
下载样例压缩包(源码+数据),并上传开发板,然后解压缩。
-
下载样例压缩包:gitee_夜雨飘零/Pytorch-MobileFaceNet↗
- 打开 gitee 页面后,点击 </br>代码 (左上角) → 克隆/下载
- 在“克隆/下载” 页面,点击 ↓下载ZIP (右上角)
压缩包文件名是:Pytorch-MobileFaceNet-master.zip
-
HwHiAiUser 用户登录开发板
用 MobeXterm 软件登录,或在本地电脑执行:
ssh HwHiAiUser@192.168.137.100或者已用 root 登录开发板,则切换到 HwHiAiUser:
su - HwHiAiUser在权限满足实验要求的前提下,尽量不用超级用户 root 做实验。
-
在开发板上新建目录:
mkdir ~/oss0526(1)该目录的完整路径是:/home/HwHiAiUser/oss0526
(2)oss 是 “open sesame 芝麻开门”的意思。 -
上传压缩包到开发板的实验目录中
用 MobaXterm 软件传文件。请参考:MobaXterm简要说明↗ | 传文件
或者在本地电脑敲命令传文件。请参考:Linux常用操作↗ | scp 远程复制文件/目录。比如进入压缩包保存的目录后,执行:
scp Pytorch-MobileFaceNet-master.zip HwHiAiUser@192.168.137.100:/home/HwHiAiUser/oss0526 -
在开发板上解压缩
先切换目录:
cd ~/oss0526再解压缩:
unzip Pytorch-MobileFaceNet-master.zip解压缩后生成子目录 Pytorch-MobileFaceNet-master,完整路径应该是:/home/HwHiAiUser/oss0526/Pytorch-MobileFaceNet-master。
3-创建环境
在虚拟环境中开展实验,可做到和开发板的其他项目互不影响。
-
HwHiAiUser 用户登录开发板
用 MobeXterm 软件登录,或在本地电脑执行:
ssh HwHiAiUser@192.168.137.100或者已用 root 登录开发板,则切换到 HwHiAiUser:
su - HwHiAiUser在权限满足实验要求的前提下,尽量不用超级用户 root 做实验。
-
用 conda 创建 Python 3.11 的虚拟环境:
conda create -n oss0526 python=3.11(1)在虚拟环境中开展实验,可做到和开发板的其他项目互不影响。
(2)oss0526 是虚拟环境的名字的样例。 -
激活刚创建的虚拟环境:
conda activate oss0526 -
在虚拟环境中安装相关包:
先安装 CPU 版本的 PyTorch 和 torchvision:
pip3 install torch torchvision --index-url https://download.pytorch.org/whl/cpu增加
--index-url ...是避免安装不必要的 nvidia 相关的包。先切换目录:
cd ~/oss0526/Pytorch-MobileFaceNet-master再安装其他需要的包:
pip3 install -r requirements.txt如果安装速度较慢(主要是下载速度较慢),可以尝试:
pip3 install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple。
✅ 可以执行以下命令,删除虚拟环境。然后重复上述2、3、4步骤,重新创建虚拟环境。
-
如果当前在虚拟环境 oss0526 中,则先去激活:
conda deactivate -
删除虚拟环境:
conda remove -n oss0526 --all
更多信息请参考:Conda指南↗
4-调通样例
先在开发板上调通样例。样例使用 GPU,开发板上没有 GPU(有类似的 NPU),先改成使用 CPU。主要涉及改动以下 3 个文件,部分目录结构如下:
Pytorch-MobileFaceNet-master
├── dataset
│ ├── lfw_test.txt
│ └── test.jpg
├── detection
│ ├── face_detect.py # 待修改
│ └── utils.py
├── face_db
│ ├── 杨幂.jpg
│ └── 迪丽热巴.jpg
├── infer.py # 待修改
├── models
│ ├── aamloss.py
│ ├── fc.py
│ └── mobilefacenet.py
├── requirements.txt
├── save_model
│ ├── mobilefacenet.pth
│ └── mtcnn
│ ├── ONet.pth
│ ├── PNet.pth
│ └── RNet.pth
├── train.py
├── utils
│ ├── predictor.py # 待修改
│ ├── reader.py
│ ├── scheduler.py
│ ├── simfang.ttf
│ └── utils.py
└── webapp.py # “5-增加Web客户端”步骤新增
-
尝试人脸识别
先进入目录:
cd ~/oss0526/Pytorch-MobileFaceNet-master/然后执行以下命令,尝试人脸识别:
python3 infer.py --image_path=dataset/test.jpg --face_db_path=face_db --threshold=0.5–image_path:待识别的人脸图片的路径
–face_db_path:人脸库图片的路径 -
AI辅助尝试解决 CUDA 相关报错
会有 CUDA(GPU相关) 相关报错,屏幕提示信息如下:
... NotImplementedError: Could not run 'aten::empty_strided' with arguments from the 'CUDA' backend. This could be because the operator doesn't exist for this backend, or was omitted during the selective/custom build process (if using custom build). ...和 AI 交流,修改相关文件,即可解决。主要修改点:使用 GPU,改成使用 CPU。
修改后,重复上述第 1 步操作。
-
AI辅助尝试解决 QT 相关报错
人脸识别后输出结果,会有 QT(显示窗口相关) 相关报错,屏幕提示信息如下:
... qt.qpa.xcb: could not connect to display qt.qpa.plugin: Could not load the Qt platform plugin "xcb" in "/home/HwHiAiUser/.conda/envs/oss0526/lib/python3.11/site-packages/cv2/qt/plugins" even though it was found. This application failed to start because no Qt platform plugin could be initialized. Reinstalling the application may fix this problem. Available platform plugins are: xcb. ....和 AI 交流,修改相关文件,即可解决。主要是 ssh 登录使用开发板,没有显示窗口。主要修改点:有窗口时,在窗口中显示识别结果;是否有窗口可供显示,识别结果都要保存为图片。
修改后,重复上述第 1 步操作。
-
测试人脸识别
python3 infer.py --image_path=dataset/test.jpg --face_db_path=face_db --threshold=0.5测试结果保存在 result.jpg 中,如下:

修改后的样例代码
能调通的样例代码如下:
请复制到相应目录中:
Pytorch-MobileFaceNet-master
├── detection
│ ├── face_detect.py
├── infer.py
├── utils
│ ├── predictor.py
5-增加 Web 客户端
增加 Web 客户端,实现 刷脸开门 功能。
AI辅助实现
可以AI辅助实现功能。一般需要和 AI 交互多轮,才能得到预期的功能。以下是多轮交互后的样例提示词,仅供参考:
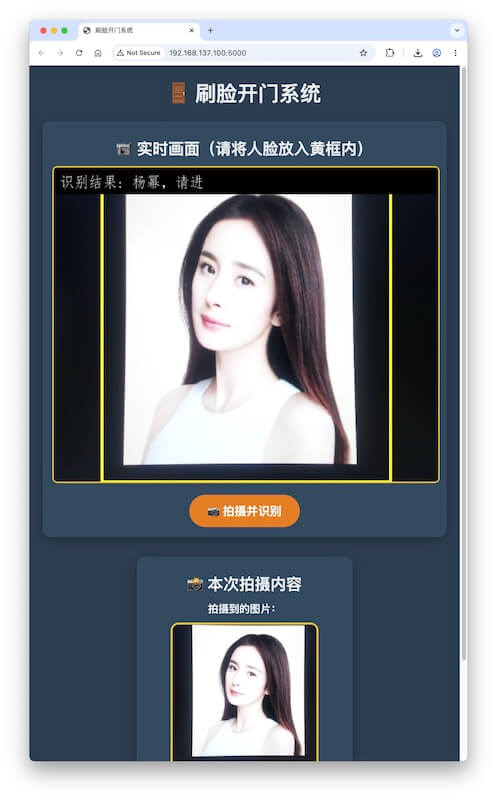
新增 Python 程序,实现“刷脸开门”的界面:
1、用连接在开发板上的USB 摄像头进行拍照
2、在浏览器的界面上,要显示摄像头的实时画面
3、在实时画面上,加个尽可能大的正方形黄框,只拍黄框内的画面。黄框和短边一样大。
4、拍摄到的图片(在黄框内),要显示在Web 界面上
5、识别结果,要显示在Web 界面上,就叠加在摄像头的实时画面里。拍到的照片中:
- 如果没有人脸,显示“没有人脸”;
- 如果有人脸,但比对后不知道是谁,显示“不认识”;
- 如果命中人脸库,则显示:对应的姓名,请进
样例实现效果:
FAQ
可能遇到的问题:
- 开发板可能有多个摄像头。程序打开的摄像头,不是外接的 USB 摄像头。
- 拍摄光线、角度,会影响识别别准确度。
增加语音播报(可选)
AI辅助增加语音播报。比如:张三,请进。
多轮交互下得到的样例提示词如下,供参考:
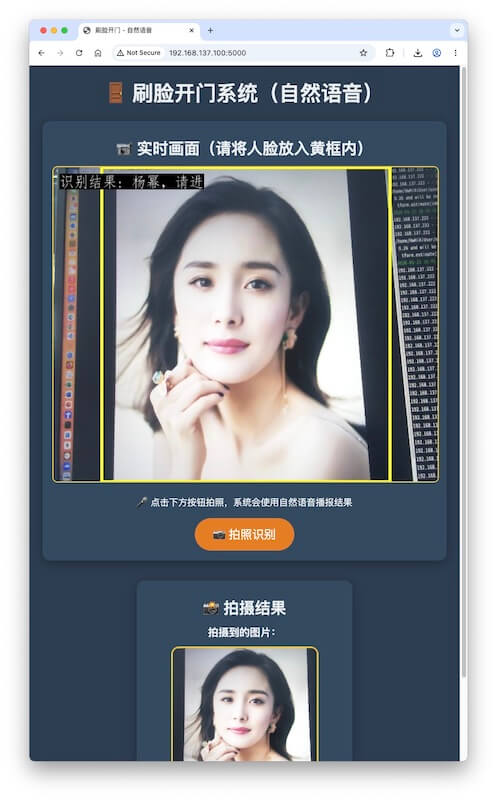
再新增 Python 程序,实现“刷脸开门”的界面。这是一个新的任务。
1、用连接在开发板上的USB 摄像头进行拍照
2、在浏览器的界面上,要显示摄像头的实时画面
3、在实时画面上,加个尽可能大的正方形黄框,只拍黄框内的画面。黄框和短边一样大。
4、拍摄到的图片(在黄框内),要显示在Web 界面上
5、识别结果,要显示在Web 界面上,就叠加在摄像头的实时画面里。拍到的照片中:
- 如果没有人脸,显示“没有人脸”;
- 如果有人脸,但比对后不知道是谁,显示“不认识”;
- 如果命中人脸库,则显示:对应的姓名,请进
6、增加语音播报
- 如果没有人脸,显示“未识别到人脸”,并语音说出来;
- 如果有人脸,但比对后不知道是谁,显示“不认识您”,并语音说出来;
- 如果命中人脸库,则显示:对应的姓名,请进,并语音说:xx,请进
- 声音要和自然语音接近,用 edge-tts
需要安装软件如下:
sudo apt update && sudo apt install mpg123
在 Python 虚拟环境 oss0526 中安装相关包:
pip3 install edge-tts
样例效果如下:
样例代码
能调通的样例代码如下:
- webv3.py:带语音播报
- test_tts.py:测试声音。可用于修改 webv3.py 中的播报声音。
请复制到目录 Pytorch-MobileFaceNet-master 中。
相关指南
可参考相关指南,已提高操作效率:
关机断电复位离开
实验结束后,请完成以下事项,再离开实验课。
-
关机断电
开发板要先关机、再断电。🚫 严谨开机状态直接断电(拔电源)!
-
归还实验器材,给实验室老师
- 开发板(每组1个)
- 开发板电源(每组1个)
- 网线(每组1个)
- USB摄像头(每桌共用1个)
- 借用的其他器材
-
椅子复位
- 每个桌子,配套 6 个椅子。请将椅子推到桌子下面。
- 西侧玻璃门,前中后靠墙,各 6 个。共 18 个。请按此数量靠墙摆放。
-
带齐随身物品
✅ 上述事项完成后,可离开实验室。
THE END